Published in CODE magazine’s weekly newsletter
May 18, 2022
By Bob Calco, Chief Architect & Lead Developer
Apex Data Solutions, LLC
Introduction
The recent rise in popularity of the functional programming, or “FP,” paradigm is evidence that FP long ago escaped the safe, top-clearance research labs of academia, and is now roaming freely in the wild.
Indeed, given recent developments in Microsoft Excel that we’ll be covering in this article, we can say now with certainty that the FP genie has well and truly left the bottle, and there is no putting it back!
And more to the point: Why would anyone want to?
FP has made its slow, winding, yet inexorable way into programming languages and environments used every day in the real world by serious professional programmers.
.NET developers discovered this paradigm with the introduction of features like LINQ (or “Language-INtegrated Query”) and lambda expressions in C# and VB.NET in the mid 2000’s. F#’s addition to the “standard language package” of .NET has further raised awareness of the paradigm among professional developers.
But over the last decade, FP has even crept into “low code” environments used by everyday people who don’t think of themselves as especially technical, let alone as developers. There is perhaps no better example than the recent introduction of the new LET() and LAMBDA() functions by Microsoft in its latest version of Excel 365.
In this article, we will discuss what FP is and how, in some ways, Excel has always been an FP environment (FPE). I will explain how these new functions bring practical “Turing-completeness” to the Excel formula programming language. Together we’ll discover how the new LET() and LAMBDA() functions bring intrinsic value to Excel spreadsheets by making it possible to create user defined functions (UDFs) “natively” in a spreadsheet using its formula expression language. This is a really powerful concept with a lot of potential.
I will then explore an alternative approach, which brings lambdas into Excel very differently, by deeply and deliberately exposing a .NET flavor of Scheme—a dialect of the venerable Lisp family of programming languages—to create UDFs. It compliments Microsoft’s direction by augmenting Excel with the extrinsic value of functional programming in a simple, direct way.
Finally, we will discuss the implications of this for data-driven financial and statistical modeling in Excel!
What Is Functional Programming?
Let’s take a step back and consider what FP actually is.
As a computing paradigm, functional programming is a bit of an onion. That is, it has layers. So let’s start peeling.
Layer 1: Everything Is a Function
The practical surface layer of the FP onion describes a way of computing that focuses computation on the processing of inputs and outputs through (you guessed it) functions, starting with the top level. That is, the entire program operates fundamentally like a function, composed of a chain of many functions, evaluating inputs to values, until there is nothing left to compute, and the program terminates. Sound familiar? It’s also how Excel’s calculation engine works.
This is in contrast to the imperative style, in which the programmer lists instructions, in sequential order, to be performed by the computer against its hardware, one at a time, from start to finish.
The first language to peel this layer off the FP onion was Lisp, invented by John McCarthy in 1958. Lisp was a conscious effort to find a simple, minimal, symbolic syntax for “lambda calculus,” a branch of mathematics formalized by Alonzo Church, that could actually run on a machine.
Unlike Fortran, the very first high-level programming language that is very firmly in the imperative camp, Lisp took the industry’s first steps in the direction of the functional approach, really just to see if such a symbolic computation-oriented language could be implemented at all. What came out of that experiment was the first language to be used seriously for artificial intelligence programming, owing to its amazing property as a language that its syntax is uniform for both data and code—there is no special distinction between them at a syntax level. This property is referred to as “homoiconicity” and it is but one of several reasons why Lisp became the first language used heavily in the early years of Artificial Intelligence (AI) research.
The key concept in Lambda calculus is, of course, the Lambda. This represents a function, which receives zero or more inputs or “arguments,” and produces an output. Formalizing this concept allowed computer scientists to envision mechanical approaches to processing that could be implemented using known technologies at the time, making it possible to conceive of how to express computations that a real computer could perform in terms that matched how a human thinks about the problem.
In other words, Church’s formalization of this as a proper calculus opened the door to implementing high-level languages, which, as you can tell from the first two languages—Fortran and Lisp—took divergent approaches from the very beginning. Eventually Fortran’s imperative programming approach led to the popular “Object Oriented” paradigm, and Lisp’s functional programming approach led to today’s concept of “Functional Programming.”
The interesting part of this story, which we’ll get to in a moment, is that Excel in a way has always been the nexus between these two divergent approaches, with object-based programming in VBA, on the one hand, and the spreadsheet itself, standing in for functional programming, on the other.
Layer 2: Immutability & Referential Transparency For the Win!
The next layer of the onion is represented by languages that provide certain “purist” compile-time and runtime guarantees about functional computation, which modern languages supporting the paradigm attempt to enforce.
These guarantees deal mainly with data immutability and what is called “referential transparency”. They are interesting, and well worth learning about, but strictly speaking aren’t concepts built into or implemented in Excel per se. So, unlike in a language that supports them natively (e.g., Clojure), in Excel they take conscious effort to adhere to.
In short, data immutability refers to an approach to state that allows values to be shared in a way that prevents conflicts and makes certain guarantees about values over time that you can reason about. It’s popular in modern languages embracing the functional paradigm in data and concurrency-intensive fields like real-time streaming where parallel processing requires discipline to get right.
The main idea behind “referential transparency” is that a function should only ever operate on the arguments supplied to it in order to produce its result. In this way, we can be guaranteed that given the same inputs, the result will always be the same. If a function relies on any other globally accessible state in the system that can change, we can no longer reason easily about its output.
This problem of reasoning about correctness used to be easier when there was only ever one core at work. Everything was sequential. The problem then was pretending that multithreading existed by emulating it at the OS level. But this somewhat idealized view of how the world would work with multiple cores relied on techniques on one core that in an actual multicore world proved impractical to rely upon using the methods that evolved on one core simulations. The reality of multiple cores exposed key weaknesses in the mutable-state, imperative programming style that had become mainstream by the time it happened.
Suddenly, the concepts of immutability and referential transparency became important even to “normal developers,” not just the theoreticians in academia. Practical new languages like Clojure, a modern Lisp that was consciously designed from first principles to adopt these functional concepts, emerged and became popular.
In terms of Excel relevance, the idea here is that most functions one uses in Excel are free of any external dependencies, taking into account only the arguments passed into them—that is, functions should be “pure” in this regard. In reality, this is achievable by writing a user-defined function (UDF) in, say, VBA, C++, or any other language that consults anything besides its formal arguments in order to produce its result.
This isn’t to say “impure” functions are “bad”—it just means extra care must be taken to reason about the result of such functions: and it should be a conscious decision. It’s essential to know which functions are pure, and which aren’t, is all. The ones that aren’t are the ones you will usually need to debug at 3 am.
Layer 3: Strong Typing Isn’t What You Think It Is
The third and “inner core” of the FP onion introduces the notion of strict functional purity, which in addition to formalizing the idea of minimizing side-effects through data immutability and referential transparency, also brings notions of strong typing, usually via algebraic type systems.
A great example of such a language is Haskell, which has pioneered “pure” functional programming with “strong” algebraic data types since the 70’s and 80’s. Indeed, the creator of LINQ at Microsoft, Erik Meijer, was a major Haskell advocate and contributor for decades, and a key player while at Microsoft in bringing Haskell’s ideas to the mainstream in .NET. He was quite open about his objectives in his paper “Democratizing the Cloud,” written in 2007.
Algebraic data types—a topic too large for the present article—are very different from the concept of types found in most object-oriented (OO) languages, where objects as types are basically data hiding or “encapsulation” mechanisms. You need a grounding in category theory and discrete mathematics to really wrap your head around this idea of algebraic types and see how very different they are from “classes” and types in the OO sense.
The important point to remember is that algebraic data types confer on compilers of functional programming languages immense compile-time reasoning powers, which make FP’s famously declarative syntax more likely to produce correct, highly efficient executable code than what a developer might craft by hand using the imperative programming approach.
But what, you ask, has any of this to do with Lambdas in Excel? Well, in a way, when you mark a particular cell or column as belonging to a particular type — such as Number or Currency or String — in a sense Excel is treating these types algebraically for the purpose of completing a calculation. So, it’s important to note that.
The good news is, you only need to appreciate and understand deeply the first layer of FP, and part of the second, as it pertains to Excel, which is more than enough to use and enjoy the benefits of the paradigm in entirely novel ways with recent new built-in LET() and LAMBDA() functions, as well as add-in extensions that are bridging the paradigm to Excel from the outside world.
Excel as a First-Class Functional Programming Environment
Now that you know what FP is, it’s time for one of those observations that is obvious only after you say it out loud, and then think deeply for a moment about it:
Excel has been the most successful functional programming environment (FPE) in history, reaching more people with the simplicity and beauty of the model than all other programming languages and IT trends that have endeavored to do so combined, and it did so almost without trying!
This curious fact—that spreadsheets by their very nature capture the essence of the functional paradigm, and users love them for that, even if they can’t explain why—seems some time ago to have caught the attention of Simon Peyton Jones, who is part of the team at Microsoft Research in Cambridge. Peyton Jones, another long-time Haskeller, was a key proponent of the new LAMBDA() function features that have finally made Excel’s curiously symbiotic relationship to FP both explicit, and intentional.
So let’s consider the proposition that Excel always was an FPE, but now it really is.
Many of us professional programmers had to reassess our initial, shall we say, unkind attitude toward JavaScript when the usefulness of its innate support for first-class functions to manipulate DOM was somewhat accidentally “discovered” with the advent of FP-oriented libraries like jQuery and lodash. In a similar fashion, so too must we professional programmers now take another, harder look at Excel as a freshly serious place to ply our software engineering craft, now that LAMBDAs are officially a thing anyone can use in a spreadsheet.
Excel is probably the most-used, most popular business productivity software in history, and it is literally ubiquitous. If one is looking for the ultimate lever with which to move the world, Excel stands out as an obvious choice.
One thing that differentiated Excel from previous spreadsheet programs like Lotus 123 was its extensibility. For a very long time now, Excel has been “programmable” in Visual Basic for Applications (VBA), allowing professional developers steeped in OO (or at least object-based) programming concepts to work with Office users to “glue” the disparate components of the Office suite into coherent back-end solutions for both small businesses and enterprises alike.
Moreover, it’s been possible to extend Excel itself with new features via “add-ins,” initially limited to adding user-defined functions in C++ via XLL libraries, but eventually expanded by Visual Studio Tools for Office to add custom panes and toolbars/ribbon tabs using .NET.
All of this explains why developers have remained interested in Excel (and Office generally) from the outside looking in. As it turns out, with the implementation of LET() and LAMBDA(), many of the things developers love about “serious” programming environments have always been in Excel, just in a form we did not recognize. Now we can look at it from the inside looking out.
“A FIXED-POINT WHAT?!”
What is a “fixed point combinator”? Microsoft Research folks seem to think everyone knows what this is, but just in case you don’t…
It comes from the classical untyped λ-calculus (of the kind made possible to run on a computer by the original Lisp), which defines something called a fixed-point combinator, known more colloquially as a Y-Combinator. Importantly, it can be used to implement Curry’s Paradox.
The key, somewhat clarifying quote from Wikipedia:
“Applied to a function with one variable the Y combinator usually does not terminate. More interesting results are obtained by applying the Y combinator to functions of two or more variables. The second variable may be used as a counter, or index. The resulting function behaves like a while or a for loop in an imperative language.
Used in this way the Y combinator implements simple recursion. In the lambda calculus it is not possible to refer to the definition of a function in a function body. Recursion may only be achieved by passing in a function as a parameter. The Y combinator demonstrates this style of programming.”
The formal Lambda calculus notation for a “Y combinator” looks like this:
| λf.(λx.(f (x x)) λx.(f (x x))) |
The equivalent in Scheme (or any Lisp, but Scheme has special support for proper recursion in the case of tail-calls, and slightly simplified syntax for calling lambdas) is a straightforward translation:
| (lambda (f) ((lambda (x) (x x)) (lambda (x) (f (lambda a (apply (x x) a))))))) |
What the term “fixed-point combinator” boils down to in practical terms is the fact that the language innately supports recursion. This is a key ingredient of making it “Turing-complete” which is a fancy way of saying it’s sufficiently general purpose to be usable to solve any problem that can be solved by a machine, at least in some finite or eventually terminating number of steps.
So when the MS Research folks are throwing “fixed-point combinator” around like it’s the best-known term in the world, just know that it relates to their explicit goal to make the formula expression language in Excel officially “Turing-complete” by making it natively recursive.
So Excel has always been a functional programming environment in which “everything is a function” not just at the surface but indeed “all the way down.” Even more surprising, it’s always been a bottom-up, Lisp-like, REPL-driven tool for developing reactive programs!
Who knew?
“Everyday users” and programmers had a lot more in common before LET() and LAMBDA(), but now, well, it’s time for … a conversation.
New Built-In Support for FP in Excel 365: LET() and LAMBDA()
So let’s talk about LET() and LAMBDA().
While LET() was introduced first, the latest version, Microsoft Excel 365 includes the much-heralded LAMBDA() function, which was announced a year ago:
The Calc Intelligence project at Microsoft Research Cambridge has a long-standing partnership with the Excel team to transform spreadsheet formulas into a full-fledged programming language. The fruits of that partnership are starting to appear in the product itself. At the 2019 ACM SIGPLAN Symposium on Principles of Programming Languages (POPL 2019), we announced two significant developments: data types take Excel beyond text and numbers and allow cells to contain first-class records, including entities linked to external data, and dynamic arrays allow ordinary formulas to compute whole arrays that spill into adjacent cells. These changes are a substantial start on our first challenge: rich, fully-first-class structured data in Excel.
In December 2020, we announced LAMBDA, which allows users to define new functions written in Excel’s own formula language, directly addressing our second challenge. These newly defined functions can call other LAMBDA-defined functions, to arbitrary depth, even recursively. With LAMBDA, Excel has becomeTuring-complete. You can now, in principle, write any computation in the Excel formula language.
Moreover, LAMBDA is the true lambda that we know and love: a lambda can be an argument to another lambda or its result; you can define the Church numerals; lambdas can return lambdas, so you can do currying; you can define a fixed-point combinator using LAMBDA and hence write recursive functions; and so on.
“A REPL BY ANY OTHER NAME, WITH AUTOCOMPLETE”
Speaking of familiar tools in unfamiliar dressing, consider the beloved REPL, or “Read-Eval Print Loop,” as Exhibit A. Most developers expect any decent language vying for mindshare these days to include one, and nearly all do. Even VBA kinda sorta has one, in the form of its limited but sometimes useful “Immediate Window.”
In a way, you can think of each cell in a spreadsheet as a mini-REPL: you type something in, and intellisense pops up with functions or the names of defined regions; then you hit enter or tab when you’re done typing, and Excel reads, evaluates your input, and prints a result!
Moreover, changing the state of one cell will immediately update the state of the entire workbook, allowing you to see instantly how the state of the entire “system” is affected by it. Errors are visually called out inline, with some suggestions about what they mean and how to fix them.
In other words, each cell is a REPL and the entire workbook is the debugger!
In terms of what coding in Excel’s LAMBDA-charged formula expression language looks like, the patterns are clear, certainly to anyone who has ever dabbled even casually in your friendly neighborhood Lisp or Scheme:
| =LAMBDA( X, Y, LET( XS, X*X, YS, Y*Y, SQRT( XS+YS ) ) ) |
The translation to Scheme is, well, just a simple matter of porting from infix to prefix notation, for the most part:
| (lambda (x y) (let ((xs (* x x)) (ys (* y y))) (sqrt (+ xs ys)))) |
Setting aside aesthetic judgments, one cannot understate what an achievement this is. The only substantive change that appears to have been made to the formula expression language besides declaring parameters and variables inside the expression is that they updated it to allow a second set of parentheses for “inline” testing. This:
| =LAMBDA(X, X*X) (5) |
Yields 25, and is the same as the equivalent Scheme notation:
| ((lambda (x) (* x x)) 5) |
However you slice it, LAMBDA() and LET() really do make it possible to write “real code” in Excel’s formula language – code that is in the Lisp and lambda calculus tradition even if its syntax is adjusted to the familiar infix notation of the formula expression language that most power users of Excel know and love.
Moreover, as noted in the sidebar, it’s truly a Turing-complete language now with full support for recursion. Purloined from Microsoft Research’s LAMBDA announcement blog, here is the canonical recursive implementation of the factorial function in action:

Figure 1a – Recursive factorial using fixed point combinator for recursion.

Figure 1b – Factorial function applied to value in A1.

Figure 1c – Factorial LAMBDA cut/paste in column B and applied against corresponding cell values in column A.
You may wonder – What more could a developer ask for to get excited about FP in Excel? I’m glad you asked!
New Add-In Support for FP with Acceλerate for Microsoft 365
Acceλerate for Microsoft 365 is a new Office add-in, initially targeting Excel, that aims to bring scripting for .NET as a general capability into the Office productivity suite. In Excel, this of course also means supporting the creation of user-defined functions (UDFs) in the chosen scripting language.
Visual Scheme for Applications (VSA) is the scripting language offered by the standard edition (the upcoming professional edition will also offer Clojure), precisely because writing lambda expressions in Scheme feels so similar to the formula expression language syntax for LAMBDA expressions. More than that, though, Scheme is ideally suited for Excel as a “companion” to Visual Basic for Applications and the formula expression language, on its own merits. It overlaps a little bit with VBA and the formula expression language, but provides two key capabilities that neither have to offer:
- The ability to write sharable code in a source control friendly way, including libraries that:
- Implement domain specific languages (Scheme is famous for “Language Oriented Programming”);
- Simplify boilerplate COM and automation code (using Scheme macros);
- The ability to wrap entire .NET framework libraries in clean, clear, idiomatic Scheme code which is much less verbose than equivalent C# or VB code—it’s at least as easy (and arguably easier) as the formula expression syntax, which is in fact grammatically much more complex.
The second point is really important to take a moment to grasp. While VBA can reach into C libraries via its foreign function interface, Visual Scheme for Applications (VSA) can reach into .NET’s vast open source and commercial markets of libraries and consume their classes natively. The entire .NET framework is at your fingertips, even in a single spreadsheet cell!
Scheme is a very small, easy to learn, and elegant language in, as has been previously noted, the venerable Lisp tradition. This means that it is also deceptively powerful. Lisps are known for their out-of-this-world macro (or as Scheme prefers to call it, “syntax extension”) capabilities.
It is simple enough to be taught to undergraduate students who have no programming experience at MIT and many other universities, and yet it is powerful enough to be used in advanced mathematics textbooks on classical mechanics[1] and differential geometry[2], as well as general software engineering [3,4]. Indeed, with not too much effort, code from these books can now be imported right into Excel!
What does the “factorial” function from Microsoft’s LAMBDA example look like in Acceλerate for Microsoft 365? The screenshot provided in Figure 2 not only gives you a flavor of how seamlessly Scheme “fits” in Excel’s new LAMBDA-friendly formula expression language, you also get a clear sense of the workflow.
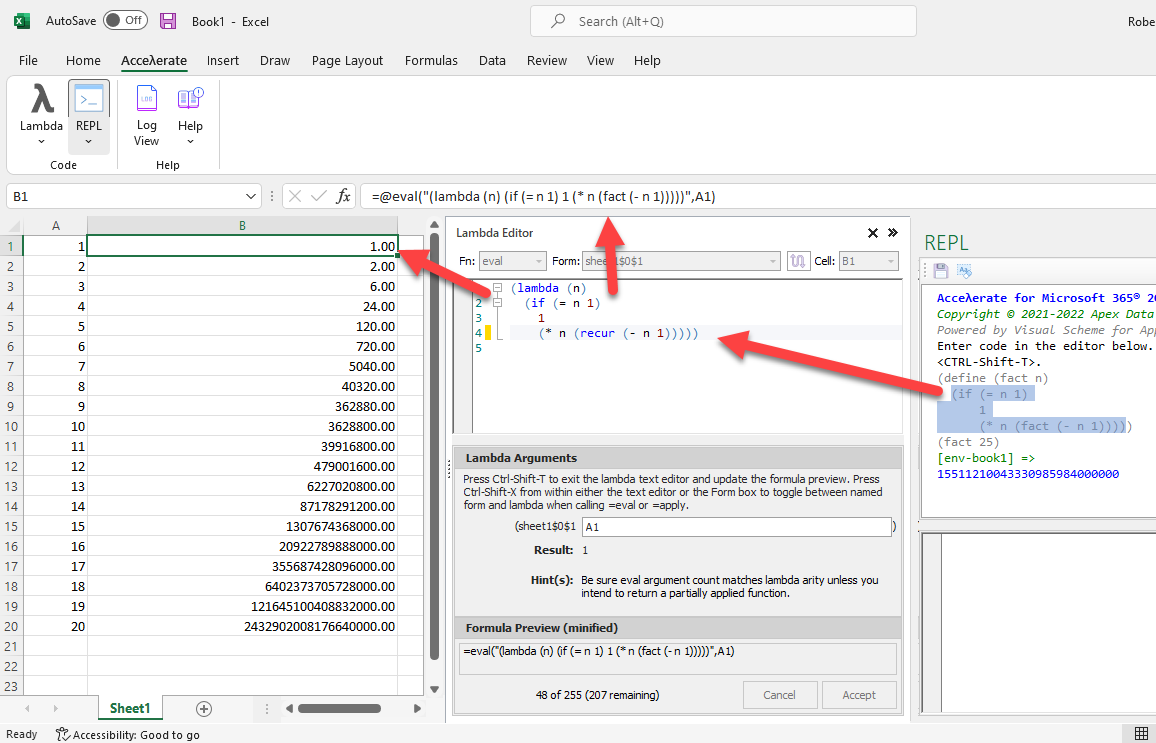
Figure 2: The REPL workflow using canonical recursive factorial example
Note also in Figure 2 that the workflow starts in a “real” REPL! This allows you to interact not just with code you are experimenting with, but also code that you pull in from external libraries, and with Excel itself—and anything else, really: databases, the web, you name it. Once you are ready to use your experimental code “for real,” you capture how you want to use it in a lambda expression crafted in the Lambda Editor.
The “recur” form in the lambda expression is how an unnamed lambda expression can “call itself” recursively, and is best suited for tail-calls because Scheme is unique among Lisps in that it supports first-class tail-call optimization.
Note the Lambda Editor makes it easy to write lambda expressions with syntax highlighting and a convenient “minify” feature to make the lambda fit as a one-liner in the formula editor bar.
Four functions basically expose the full power of Scheme in Excel:
- =λ(<lambda-expr>[,a1,a2,…,aN])
- =define(<name>,<lambda-expr>[,a1,a2,…,aN])
- =eval(<name-or-lambda-expr>[,a1,a2,…,aN])
- =apply(<name-or-lambda-expr>,<range>)
The =λ() function allows you to specify an unnamed lambda expression and optionally call it with arguments.
The =define() function allows you to give a Scheme name to a lambda expression so that you can call it by name many times without having to recompile it each time. Compilation and execution speed are very fast—it’s all .NET under the hood—but nevertheless an oft-used function should have a name and only be compiled when it is changed. You can then also give the cell where it is defined an Excel name, which will make it available via the formula bar editor’s built-in “intellisense.”
The =eval() function allows you to pass arguments to a named or inline lambda expression. It can be used instead of the greek letter version, but can also take Excel names or cell references pointing to named lambdas in other cells.
Finally, the =apply() function allows you to use Scheme or your own defined variadic functions—that is, functions that take zero or more arguments as a list. This is a common idiom in Lisp and makes it very easy to deal with dynamic arrays and regions. The only challenge comes in when you are dealing with 2D regions, since you have to make a choice in ordering: by-row (which is the Excel default) or by-column? Some helper functions allow you to deal with this very simply.
A video of this capability in action is available at www.apexdatasolutions.com, but just so you can see how little code is necessary to move what would otherwise be mountains, here are the relevant code snippets that show how easy it is to leverage .NET to solve a practical problem when working with Scheme functions that you apply to 2D regions in Excel. The somewhat contrived example is composing sentences from words jumbled by row and by column (please watch the video first, then the code will make sense!).
Listing 1: join-words:
| (lambda (words delimiter) (clr-static-call String (Join String Object[]) delimiter (list->vector words))) |
Listing 2: words->sentence:
| (lambda words (string-append (join-words words ” “) “.”)) |
Listing 3: using (flatten lol) in an inline “apply” lambda:
| (lambda lst (apply words->sentence (flatten lst))) |
Listing 4: using (flatten-by-column lol) in an inline “apply” lambda:
| (lambda lst (apply words->sentence (flatten-by-column lst))) |
Notice that join-words in Listing 1 uses the (clr-static-call …) form to call into the static Join method of the static String class defined in .NET. This is a trivial sample of what .NET interoperability looks like in VSA; keep in mind that .NET also supports native foreign function interface, and so naturally VSA does, too.
There is so much more than can be said, both about Scheme as the “Third Musketeer” of Excel programming languages, and about how easy and fruitful it is to reach right into .NET to pluck a ready-made solution that otherwise would be inaccessible and need to be reimplemented. But the upshot of it is this: VSA brings both a proper Scheme and the reach of the vast .NET framework right into Excel as if they’ve always been there.
Leveraged in conjunction with Excel’s new LET() and LAMBDA() functions and as a companion to VBA on the interoperability and automation side, VSA brings functional programming power from two different but now deeply interconnected traditions right to a spreadsheet developer’s fingertips.
“BROTHER, CAN YOU PARADIGM?”
A subtle point about Scheme worth briefly noting is that functional programming is but one of many paradigms the language was designed to support. Under VSA’s hood is a library called “tinytalk” intended as a proof of concept for a Smalltalk-like object-oriented “language” implemented using syntax extensions. This is just one example.
What other paradigms are there? Well, one very important paradigm that Scheme is famous for “democratizing” if you will is logic programming, what computer scientists prefer to call “relational” programming. Also under the hood in VSA is the famous minikanren library: a surprisingly small, pure Scheme library that implements real logic programming (hence the name – “kanren” is Japanese for “relation” and Oleg Kiselyov, who wrote the original version of minikanren, happened to be living in Japan at the time).
The library makes it easy to take a standard Scheme function and turn it into a relational function. For example, the (append …) form takes two lists, and appends them into one list. A “minkanren-ized” version of this form, (appendo …), does the same thing in the context of a logic query. Here is a function that, given a list, will output all the possible append operations that would append two lists in order to create it:
| (define appendos (lambda (a-list) (run* (q) (fresh (x y) (appendo x y a-list) (== q (list x y)))))) |
So given the following input
| (appendos ‘(1 2 3 4 5)) |
You get the result:
| ((() (1 2 3 4 5)) ((1) (2 3 4 5)) ((1 2) (3 4 5)) ((1 2 3) (4 5)) ((1 2 3 4) (5)) ((1 2 3 4 5) ())) |
Why is this important? Well, it means this pure-Scheme power is available to you to break out of the deterministic limitations of the spreadsheet model. It’s possible to bring finite domain constraint solving functions, stochastic modeling methods, and much, much more right into Excel as a now unlimited, fully data-driven, .NET powered modeling environment.
Speaking of data, another thing to check out under the hood is a set of “purely functional data structures,” in the (pdfs) library, which are based on the idea of data immutability. Space constraints prohibit an in-depth example, but the implementations are Scheme ports from examples in Okasaki [5].
Conclusion
Functional programming is a large subject with a rich and surprising history in the field of computer science. Its relevance in recent years has grown as multicore CPUs have exposed the previously-masked complexities of the imperative style for concurrent processing. Meanwhile, users of business productivity tools like Excel have already grown used to FP’s more declarative style of “programming,” even in business artifacts as seemingly mundane as spreadsheets.
The recent addition of the LET() and LAMBDA() functions to Excel’s formula expression language has made explicit the relationship between Excel and FP that has quietly been winning over converts to the functional paradigm from among the ranks of non-programmers for decades. They give developers a bird’s-eye view of the value of FP to “normal people” but more importantly they make professional programming skills even more relevant and applicable than ever to the world of spreadsheet development.
The integration of Scheme on .NET into Excel’s unique user-developer nexus brings additional practical possibilities and a smorgasbord of new programming patterns and paradigms to the storied Excel and Office vision. It is a vision of interoperability at every level—in code, in data, and everything in between—that will be realized everywhere, not just on the desktop, or on Windows, or in somebody else’s Cloud. This trio of technologies make it easier than ever to turn document artifacts into active players in the world of linked-data microservices, where everyone can be their own cloud. But more on that, later.
—-
Works Cited:
[1] – Sussman, Gerald Jay & Wisdom, Jack. Structure and Interpretation of Classical Mechanics, 2nd Ed. (2014, MIT Press)
[2] – Sussman, Gerald Jay & Wisdom, Jack. Functional Differential Geometry. (2013, MIT Press)
[3] – Abelson, Harold & Sussman, Gerald Jay. Structure and Interpretation of Computer Programs, 2nd Ed. (1996, MIT Press)
[4] – Hanson, Chris & Sussman, Gerald Jay. Software Design for Flexibility: How to Avoid Programming Yourself into a Corner. (2021, MIT Press)
[5] – Okasaki, Chris. Purely Functional Data Structures (1998, Cambridge University Press).